Working logic¶
The core mission of this tool is to convert medical laboratory observations from electronic health record into phenotypes coded in Human Phenotype Ontology terms. The app divides this goal into three subgoals:
- Map LOINC into candidate HPO terms. Each LOINC code corresponds to a set of HPO terms. For example, Loinc
10449-7("Glucose in Serum or Plasma -- 1 hour post meal") will be mapped toHyperglycemia,hypoglycemiaandAbnormality of blood glucose concentration. - Retrieve resources from EHR systems. The app relies on EHR system that complies with FHIR standards. The most critical resources that are relevant to this app are
ObservationandPatient. - Convert
Observationinto HPO terms. The app checks the outcome of anObservationand output the corresponding HPO term using the map generated in the first step.
In the following sections, we will discuss those goals in details.
Mapping LOINC to candidate HPO terms¶
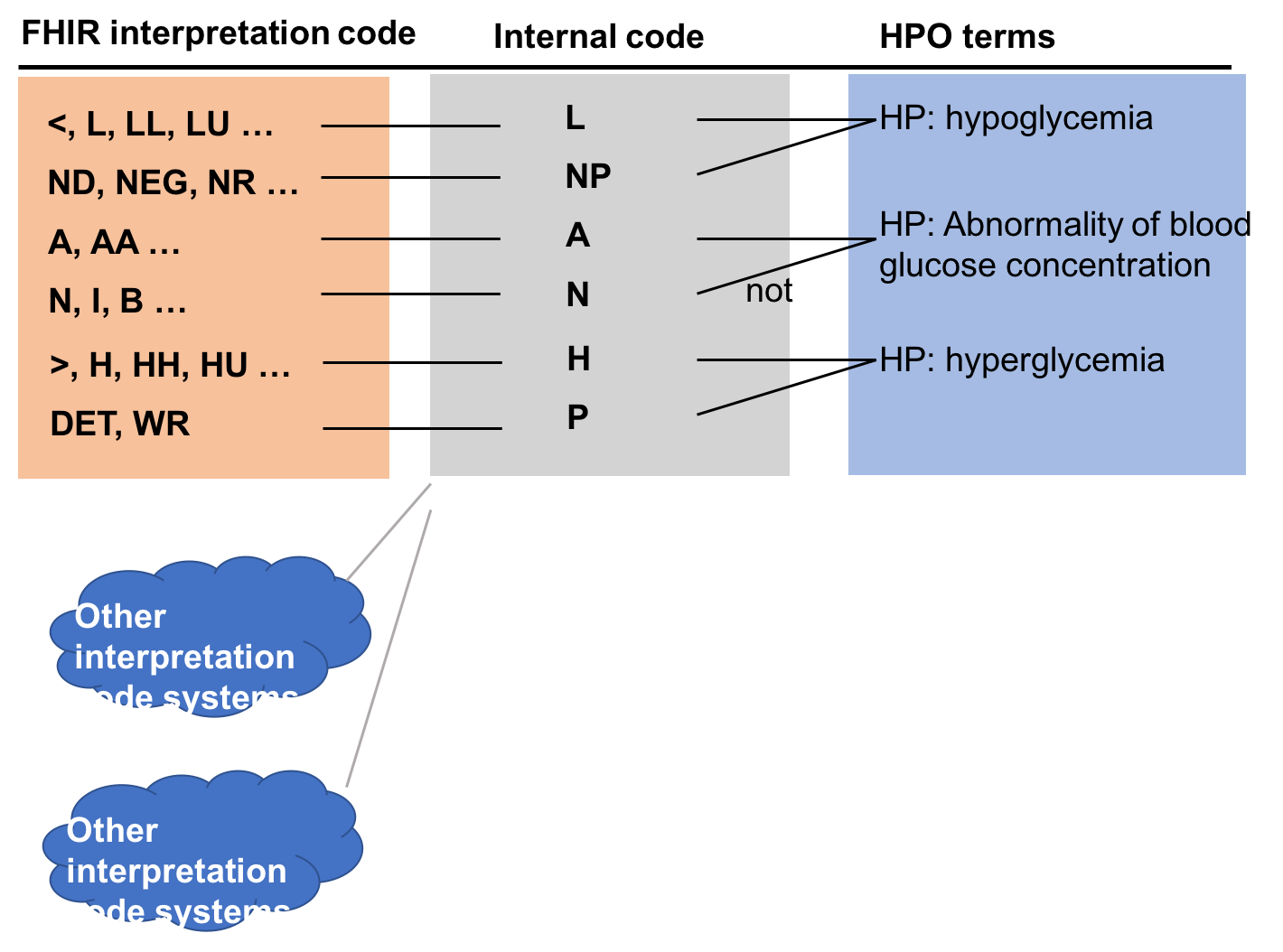
LOINC observations have four main categories, quantitative(Qn), ordinal(Ord), nominal (Nom) and narrative(Nar). The majority of them are Qn (~50%) and Ord (~26%) and a smaller percentage are Nom and Nar type (<10%). The outcome of Qn and Ord type observations are typically represented with a code from the FHIR interpretation code valueset. Some examples are L for “low”, LL for “critically low”, or NEG for “negative”. The full valueset is included in Table 2. Therefore, if we map those interpretation codes to a candidate HPO term for each LOINC, we will be able to convert an observation into a HPO term.
However, the FHIR interpretation code valueset has 39 codes. It would be a massive task if we need to map 39 HPO terms for each LOINC code, let alone there could be more than one interpretation code system for different EHR systems. Fortunately, many interpretation codes are similar (e.g. FHIR L and LL both represent “low” but at different severity). So we picked 7 FHIR codes as our internal code to simplify the annotation job. Instead of annotating each each interpretation code, we will first map an interpretation code valueset into this internal FHIR subset (Table 1). Then we just need to annotate 7 values for each LOINC code (actually 6 because “U” does not need an annotation) instead of 39. Table 2 shows the map between FHIR interpretation code valueset to the FHIR subset. Similar maps can be built to deal with other interpretation code systems.
Table 1: Internal Code System
| code system | FHIR |
|---|---|
| Code | Meaning |
| A | abnormal |
| L | low |
| N | normal |
| H | high |
| NEG | not present |
| POS | present |
| U | unknown |
Table 2: FHIR interpretation code set Mapping to internal code system
| FHIR interpretation code value set | internal FHIR subset | ||
|---|---|---|---|
| system | http://hl7.org/fhir/v2/0078 | FHIR | |
| Code | Meaning | Code | Meaning |
| < | Off scale low | L | low |
| > | Off scale high | H | high |
| A | Abnormal | A | abnormal |
| AA | Critically abnormal | A | abnormal |
| AC | Anti-complementary substances present | POS | present |
| B | Better | N | normal |
| D | Significant change down | L | low |
| DET | Detected | POS | present |
| H | High | H | high |
| HH | Critically high | H | high |
| HM | Hold for Medical Review | U | unknown |
| HU | Very high | H | high |
| I | Intermediate | N | normal |
| IE | Insufficient evidence | U | unknown |
| IND | Indeterminate | U | unknown |
| L | Low | L | low |
| LL | Critically low | L | low |
| LU | Very low | L | low |
| MS | Moderately susceptible. Indicates for microbiology susceptibilities only. | U | unknown |
| N | Normal | N | normal |
| ND | Not Detected | NEG | not present |
| NEG | Negative | NEG | not present |
| NR | Non-reactive | NEG | not present |
| NS | Non-susceptible | U | unknown |
| null | No range defined or normal ranges don’t apply | U | unknown |
| OBX | Interpretation qualifiers in separate OBX segments | U | unknown |
| POS | Positive | POS | positive |
| QCF | Quality Control Failure | U | unknown |
| R | Resistant | U | unknown |
| RR | Reactive | POS | present |
| S | Susceptible | U | unknown |
| SDD | Susceptible-dose dependent | U | unknown |
| SYN-R | Synergy - resistant | U | unknown |
| SYN-S | Synergy - susceptible | U | unknown |
| TOX | Cytotoxic substance present | POS | present |
| U | Significant change up | H | high |
| VS | Very susceptible. Indicates for microbiology susceptibilities only. | U | unknown |
| W | Worse | A | abnormal |
| WR | Weakly reactive | POS | present |
We can make the annotation task even easier. If we analyze our internal codes carefully, NEG (“not present”) and “POS”, resenting an outcome that the measured value is only applicable to Ord type of LOINC that has “present” or “absent” as its outcome. On the other hand, “L”, “N”, “A”, “H” only apply to Qn type of LOINC. “A” and “N” will map to the same HPO term but have opposite negation value. What this means is that we only need to map 2 HPO terms to Ord LOINC with “presence”/”absence” outcome and 3 HPO terms to Qn LOINC.
The following graph summarize the annotation process and how the app convert a LOINC observation into HPO terms. We pick three HPO terms for each LOINC code, representing the desired phenotype to assign for the patient when the observation value is low, intermediate, or high. By default, those three terms will be mapped to the internal coding values, which further map to external code values used in real world.
- note:
Ord``(non-"presence"/"absence" outcome), ``Nom and Nar observations can use other coding systems that are more difficult to handle. For example, Loinc 600-7 or “Bacteria identified in Blood by Culture” may use a SNOMED concept to represent the finding that Staphylococcus aureus is detected:
"coding":[
{
"system": "http://snomed.info/sct",
"code": "3092008",
"display": "Staphylococcus aureus"
}
]
To handle this type of outcomes, we allow annotating LOINC codes in the “advanced mode”. Under this mode, the user will assign a code from the coding system into a HPO term. In the above example, the user will say:
"system": "http://snomed.info/sct",
"code": "3092008"
map to HP: Recurrent bacterial infections. This workflow is actually what we used in the backend for annotating internal code values, but now user has to annotate in a more explicit way.
Retrieve Resources from EHR systems¶
We hope to allow at least two use cases with this app in real world. One is to allow patients to look at their own results, or allow physicians to look at a patient’s results. The second case is to allow academic researchers to retrieve a large cohort of patients and get a large data set containing patients’ phenotypes. The technology to handle both cases are very similar: both relies on REST api and a hapi-fhir Java library handles this task very nicely. We define a filter, either patient-specific or non-specific, and we retrieve patient resources from hospital EHR systems; then we can use a patients ID to retrieve all observations related to the person.
Convert Observations into HPO terms¶
We will describe how the app attempts to convert an observation into a HPO term in this section.
The app first tries to use the interptretation field in an observation. If there is one, the app checks whether we have a HPO term assigned for it. If there is one, it would be the desired output; but more likely there won’t be one. In the latter case, the app will try to convert the interpretation code into an internal code using the maps described in Table 2. If the app finds an internal code successfully, it will output the corresponding HPO term; if it fails or it cannot find a HPO term for the internal code, it will go to the next step.
If the first attempt fails, either because there is no interpretation field, or using the interpretation field did not find an HPO term, the app will check the value field. The first scenario is that it finds a coded value for the observation. In this case, the app will check whether there is a HPO term assigned for it and output the result if there is one. The second scenario, which is more likely in theory, is that there is a numeric value as the outcome of the observation, which means that the app has to make the last attempt to find the correct HPO term.
The central mission for the last attempt is to compare the measured value with the reference ranges, convert it into an internal code and then output the corresponding HPO term.